The Shanten Parser
In which I fight man and god to get a number to show up on a mahjong table.
Background
Riichi mahjong is, fundamentally, a card game played with a different deck.
A set of tiles for riichi mahjong. Art by FluffyStuff.
Tiles are typically used for playing the game physically, a commonality with many other mahjong games. There’s actually lots of different mahjong games, many named after place of origin (riichi is also called “Japanese mahjong”; off the top of my head, I can name Chinese, Hong Kong, Filipino, British and American mahjongs, but there’s also Sichuan Bloody and probably a whole lot of others). The basic theme connecting the various mahjongs together is converting the random allotment of tiles you get at the start of the game to a hand made entirely out of multitile melds; you do this by drawing one tile per turn and discarding another.
In riichi mahjong, you have thirteen tiles in your hand, so this works out to be four three-tile melds (a run of consecutive tiles or a triplet of same-faced tiles)1 and one two-tile meld, a pair of tiles with the same face. However, there’s a catch: you need fourteen tiles to make all those melds, one more than you can hold in your hand—so, at best, with a standard hand, you’re going to have a meld waiting for its last tile while the rest of your hand is already complete. In riichi mahjong, this state is known as “tenpai”—where just one additional tile would bring your hand to being 100% melds. Once your hand is complete—and if you’ve met at least one of a number of other requirements (most of which having to do with the specific combination of melds in your hand)—you can win the round right there and then, without having to discard.2
So, in riichi, you want to have a complete hand, and in order to get a complete hand, you must get into tenpai. There’s a concept in riichi known as “shanten”—it’s the number of best-case draws between you and tenpai. There’s formulas for it, and for standard hands it’s 8 - 2*CompletedMeldCount - IncompleteMeldCount - {one or more pairs: 1; no pairs: 0}. As for nonstandard hands, riichi mahjong has but two of them. These two hands can still win the round despite not consisting of four three-tile melds and a pair: chiitoitsu, seven pairs (an immigrant from American Mahjong; usually abbreviated as chiitoi) and kokushi musou, thirteen orphans (sometimes abbreviated as kokushi), which has twelve different, unmatched tiles and one, single pair, but must be made of an extremely specific combination of tile values. Each of these special hands requires their own formula for shanten; chiitoi’s is 6 - DistinctPairCount3 and kokushi’s is 13 - DistinctNonsimpleTileCount - {one or more nonsimple pairs: 1; no nonsimple pairs: 0}, where a “simple” tile is a tile numbered 2-8, and a nonsimple tile is everything else. As shanten is concerned with the best-case scenario, the final shanten of the hand is the minimum of these three measurements (that is, we measure the distance along the shortest path to completion4). This means that the worst possible shanten is actually 6—even if we had a hand that was wall-to-wall disconnected tiles with nowhere near enough nonsimples to bring us near kokushi, we still have the out of drawing six tiles that are each duplicates of some other tile in our hand to make chiitoi. Also note that shanten cannot increase with the addition of new tiles; there are no terms that add to the calculated shanten past the base value, only ones that subtract. Thus, with each draw, we either improve our shanten or make no change; shanten can only get worse when we discard, either by breaking up a completed meld or tearing apart an incomplete one. Shanten also does not go down indefinitely—not because the formulas say so, but because we simply don’t have enough tiles in our hand to make it do so. With 13 tiles, the best we can get is 0—that is, our hand is, at last, in tenpai,5 which means all that we need is one single lucky tile to make our hand complete—and a fully completed hand, with 14 tiles, has a shanten of -1. Our goal is to add the ability to measure shanten to a preexisting riichi mahjong game engine—an already heavily-modified version of AozoraMahjong—which is implemented within VRChat.
VRChat is a voice chat application with spatialized audio. Spatialized audio allows for voice chat meetings of large groups; the maximum number of active participants in a conversation is four people6, and one giant voice chat with everybody at the same volume doesn’t allow for people to organize themselves into groups small enough to have a conversation—everybody can hear everybody and nobody can hear anybody. The volume falloff of spatialized audio allows for groups to self-organize into subgroups that can have functional conversations and can merge and splinter and transfer units just as naturally and as subconsciously as conversation works at a party. In order to have spatialized audio, one must have a space for that audio to exist within. VRChat uses Unity to render this space. In VRChat terminology, this space is called a “World”, which is a Unity scene object uploaded by a VRChat user.
A Unity project with a default Unity scene, as generated by the VRChat Creator Companion for use in creating VRChat worlds7
The objects contained within this scene are scriptable—for a variety of purposes—but as VRChat worlds are untrusted content, the scripting is not done with Unity’s built-in system of C# scripting. Instead, VRChat uses a technology known as Udon, which by default presents itself as a visual programming language (nodes connected with wires and whatnot) that is compiled to bytecode and executed by VRChat in a VM at runtime. However, there is an alternative to this—an alternative that, as far as I know, everybody uses—which is to use a program known as UdonSharp to compile a subset of C# (I will call this subset U#) into Udon bytecode. The existing mahjong game that we have purchased for modification and use is entirely U#. Thus, in order to calculate shanten, we will be using U#.
Problem
So, at this very moment, the problem seems to be fairly straightforward; the shanten formulas are pretty simple, we’ve got a subset of good ol’ C# to work with, and we’re actually building upon a preexisting mahjong game that’s relatively popular and battle-tested, at least among the niche we’re operating in. Smooth seas ahead, right?
If that was the case, there wouldn’t be a writeup, so you’re probably waiting for the catch.
It’s actually not one catch, it’s a whole stadium of them. Let’s start with the one that got me roped into this whole mess and the reason I refer to this program as a parser: mahjong hands are, by design, highly ambiguous. There’s many ways to make a game hard, and riichi mahjong primarily goes for computational complexity. This makes the game a small nightmare to program for.

Even seasoned, commercial devs, used to the particulars of game development and also building off an existing implementation, can find themselves enmired in bugs—there’s only supposed to be four of the same tile in a mahjong game, not seven! From a programming standpoint, riichi is a wily beast, full of pitfalls and edgecases and ready to completely fall apart if you are not on top of everything. There’s other computational nightmares lurking in the wings, but, today, we’re focused on shanten. What makes shanten gnarly is that that ambiguity mentioned above is geared up and ready to wreck our day; while shanten formulas themselves aren’t hard, actually counting up the pieces they use is. Let’s start with the most basic ambiguity. A run, in riichi, is three consecutive tiles of the same suit. Runs do not wrap around, so there’s seven possible runs (that is, a run cannot start at 8 or 9 of a suit, because you run into the end of the suit before you can complete the run). Let’s take ourselves an example run, say the 2, 3, and 4 tiles of the pinzu (circle) suit, or 234p, for short. For shanten purposes, this is a run, right? We add one to the CompletedMeldCount and move on, right? Well, it’s also three protoruns: 23p, 24p, and 34p. Completed melds give us -2 shanten per meld and partial melds give us -1 shanten, so is this completed run actually three incomplete runs and thus -3 shanten? Nope—a tile can only belong to a single group at a time, so this trio of tiles could be a run, -2, or a protorun with a lone tile attached, -1; to try and parse that trio as more than one protorun would require counting at least one tile as a member of multiple groups: 23p, 34p double-counts the 3p. So far, so good: there’s a pretty clear best parse here, and we only want the best parses, because shanten is about the best-case scenario. Everything else is irrelevant and must be discarded.
But let’s add another tile to the mix. Let’s say we draw a 3p. Now we have 2334p—what is this? Is this a run plus a lone tile; 234p, 3p? Is this two protoruns; 23p, 34p? Is this a protorun and a pair; 24p, 33p; or is it a protorun and a prototriplet; 24p, 33p? If these are all the pinzu-suited tiles we have, it’s all of them, for they all have the same effect on our shanten, -2.8 If we have more pinzu tiles in our hand, then we may be able to form different groups that give us better shanten. If there’s another pair in the hand, parsing 2334p as containing a pair instead of a prototriplet may not give us the best shanten; after all, we only need one pair in our finished hand—unless we’re going for chiitoi. Riichi thrives on putting players in situations where the best path forward isn’t clear. Let’s say that 2334p is all the pinzu we’ve got, and the rest of the tiles we have are a mix of souzu (bamboo) and manzu (character) tiles;9 let’s say that your hand looks like this: 334455m2334p667s. This hand has a shanten of 1—it only needs one lucky draw to get into tenpai—but it actually has it in two separate ways. It’s 1-shanten10 chiitoiwise: there’s five distinct pairs in the hand, so for chiitoi shanten that’s 6 - 5 = 1—but it’s also 1-shanten as a standard hand; we could parse it as a whole bunch of runs with leftovers like 345m345m234p3p6s67s, or like 345m345m23p34p66s7s, or like—actually, let’s ask the parser what it thinks of this hand.

Nine. Nine distinct parses, all yielding the same shanten.11 Thankfully, tile-grouping ambiguity can’t reach across suits (although pairs in one suit influence the value of pairs in another)—but what if you had a hand that was completely made up of one single suit? Say, for instance, you had 1112345678999s?
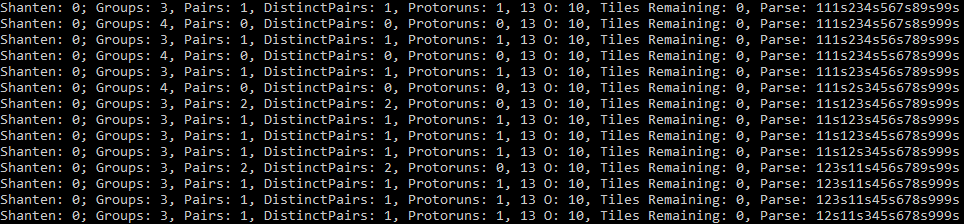
Ach! Now there’s fourteen of them!
It can get worse than that. It can get much worse than that. See, the farther away you are from tenpai, from being ready, the more tiles you have that aren’t hard locked into particular shapes. That’s more tiles that are easily able to swap around and make up different protomelds without affecting the shanten of the hand. I ran some numbers on the dataset I used to test the parser with (comprising 900900 hands), and the most ambiguous hand in there—by count of the number of parses that consumed the whole hand—was 13568m3467p35689s, with shanten 4 and 163 different parses!12 It’s important to note that while shape (pair vs prototriplet, etc) ambiguity does not extend across suits, the fact that a pair only counts for a standard hand once means that tiles in one suit can still affect what the best parse is for tiles in another suit; the end number of parses is not the number of ways to parse each suit all multiplied together, it’s actually a little less. That small caveat of global behavior comes barreling in from the sky to obliterate hopes of shortcutting by parsing each suit in total isolation—this shortcut cauterization is not uncommon when programming riichi. We’re not guaranteed to be able to split the hand up by suit to get coherent shanten parses, so we have to take the whole hand into account as we’re parsing the thing (RIP divide-and-conquer).
But hold on. This is a card game, right? Do we really need to be clever? Couldn’t we just brute-force it in some way? I’ve got 4GHz in my processor, surely four billion clocks per second will get us pretty far; who cares if it takes 1ms or 10ms or, hell, 100ms per hand? All of those should be plenty fast enough for a number to update in the corner of a screen. The time we spend being clever, the time we spend maintaining it—could those be more effective elsewhere? Is the effort we’re about to put in actually going to actually improve anything?
If this were any other realtime programming environment, 100ms for updating a number onscreen would be unfortunate, but ultimately acceptable. But we’re working in Udon, and Udon is by far the worst programming environment I have ever worked in, realtime or not. I can say exactly one good thing about it: to my knowledge, nothing has escaped the Udon runtime. This is an incredibly high bar and should be high praise, but unfortunately, it’s kind of achieved through brute force; Udon’s security design is approximately equivalent to building an armored car using meter-thick steel walls—sure, no bullets are getting through, but your tires are about to burst, you can’t go over bridges, you gotta put your foot to floor just to get the thing to budge—and god forbid you so much as catch sight of a hill; your engine may just explode out of fright.13 Udon’s own documentation claims you should expect a slowdown of 200 to 1000 times. This turns your decent, 4GHz CPU into a 4MHz microprocessor from forty years ago. No, not each one of your cores, your whole processor, because Udon is single-threaded. Not only is Udon single-threaded, in violation of the first principle of GUI programming for the past thirty years, every single Udon script runs entirely on the main thread.
It is difficult to express just how catastrophic these decisions are, because they all compound each other—and are all made quite literally ten times worse by VRChat being a realtime program that is strapped to your head: if Udon didn’t run on the main thread, its poor performance could be mitigated at the cost of extra latency by letting VRChat’s main thread continue to update and display the world while the scripts compute away in the background. The same mitigation—in a stronger form, but with more legwork—could be performed by the programmer themself if Udon allowed for the ability to launch background threads. But VRChat stalls all rendering to run Udon scripts, which themselves run through molasses14. This is a horrific hazard in any realtime application, but again, VRChat is strapped to your head; in its intended use case, it has complete control over your field of view. The performance requirements for head-mounted displays are strict; the head is constantly moving, generating visual feedback that the brain uses as part of its balance system. In the worst case, a collection of missed frames at the wrong time could cause somebody to fall over, potentially causing serious injury to themselves, their surroundings, or the expensive display strapped to their face, and possibly all of the above. In theory, bad performance could actually cause physical injury, which is a slightly rare occurrence in consumer software.15
So we’ve got a performance budget imposed by externalities, and it’s likely to be tight. What kind of budget are we talking, here? Unfortunately, I am not a human vision expert (I just know some slightly uncommon things), but I don’t have to be.16 The performance budget we care about is actually determined by the headset on the user’s face, as the display panel itself updates at a fixed refresh rate. This means that if we’re not done rendering this frame in time for the display, it has to reuse the last frame we sent, a frame that doesn’t take into account the new position of the user’s head.17 Native HMD refresh rates seem to vary between 72-120Hz, depending on headset.18 While refining the shanten parser, I used the refresh rate of the headset I had on hand, an Oculus CV1; this headset refreshes at 90Hz natively, giving us a per-frame budget of 11.1ms. Unity, like most modern game engines, doesn’t wait for the GPU to finish work on the frame it just finished doing all the CPU work on before it starts doing CPU work on the next frame, so we have 11.1ms of CPU time—but that’s 11.1ms that has to be shared among the entirety of the engine. There’s basic Unity stuff, there’s the rest of VRChat, there’s the other Udon scripts in the world—including the rest of the mahjong game this calculation is part of. We actually have nowhere near 11.1ms to ourselves. I decided I had a 1ms CPU-time budget; this was not a scientific estimation and honestly it felt like sort of a sandbag, but it seemed like there should be a spare milli lying around; if I knew more about Unity profiling, I could have had a better estimate, but I was more interested in forging ahead—and I had a backup test: if my frametimes still cratered on drawing a tile, then I’d have more work to do.
Yes, “still”: if, during the course of a round, your draw brings your hand into tenpai and you haven’t taken any tiles from anybody else’s discards, you can cry “riichi”, throw a thousand points on the table, and sit back and relax with your hand locked in place while everybody else plays the game around you, every single one of them knowing you are now one lucky tile away from winning the round. Whether or not a riichi implementation knows or cares about shanten, it must be able to tell whether or not a hand is in tenpai in order to show the riichi button, unless it’s just aiming to be a space to move tiles around and let players themselves operate the rules. The mahjong game that we’re modifying is aiming to provide a pretty automatic experience, so, by necessity, it has a tenpai check in it. Unfortunately, it’s a rather slow one; it starts by iterating through each of the fourteen 13-tile subhands within a hand that has just drawn a tile and goes downhill from there. Stock, the resulting stall upon drawing a tile can be long enough to make VR middleware think VRChat has locked up, resulting in the world around you freezing into a floating rectangle inside the starry void of the SteamVR home while Udon sorts itself out.
To make this less bad, my SO managed to divide the tenpai check from one giant stall into having each of its iterations take place on consecutive frames (this is an old realtime performance technique, by the way; if you’ve ever swung a camera around in a videogame and watched stuff pop into existence as you turn, you’ve seen this in action; that’s an occlusion check with a latency of one frame unhiding stuff just after it becomes visible rather than stalling the render to find out if it should show up or not beforehand). This change was highly invasive; the existing riichi implementation was not designed to operate like this and the result was some rather ugly internals as a consequence—but it worked. Spreading out the existing tenpai check turned the game locking up on every draw into…14 frames of 20Hz video strapped to your head.19 20 The little chime to tell you it was your turn was still more of an alarm instead of a convenience—Warning, framedrops ahead!—but it was better than the total stall. However, when my SO came to me with the idea of calculating shanten, we realized that if shanten calculation could be done with anything approaching reasonable performance, we could replace the existing tenpai check and just have the game check for a shanten of zero instead, both adding a new feature and significantly improving performance and comfort at the same time.
However, there’s another problem that causes issues all throughout AozoraMahjong and is likely the progenitor of the aforementioned tenpai-checking solution that locked up the main thread: U# itself. U# has significant restrictions imposed upon it by the Udon VM it ultimately runs within—and at least one behavior (likely a bug) that cost me some hair in figuring out what the hell was going on. My initial proof-of-concept for The Shanten Parser was actually written ignorant of these restrictions, which necessitated a bit of soul-searching (do I really want to do this cursèd thing?) and then a conversion of what I had written into a form (a cursèd form, for U# corrupts all that it touches21) that would work within the confines of U#. Speaking of, let’s get to those confines: no dynamic allocations. No instantiation of user types at all. No creation of Unity objects. Most of the C# standard library—and most importantly for this case, the entirety of its built-in collections—are not allowed. So we have integer types, floating-point types, strings, statically-allocated arrays, and Unity objects (which we cannot make more of) to get our work done with. If you want dynamic memory of any sort, you’re doing cursed string manipulation. Enjoy. Also, no enums.
Oh, and about that probable bug? UdonSharp will happily compile a U# program with a new[] outside of the Start() method without warning or error, but there is apparently a hidden cap on array sizes doled out outside of Start() (including C#’s syntax-sugar static allocations) that will change on you without warning, rhyme, or reason. I don’t remember the exact numbers, but it was something on the order of a 6,000-element cap suddenly transforming into a 400-element cap between builds on the same machine with the same settings—when the array was supposed to have 65,535 elements. (No, that’s not overflow or typo; the shipping version of The Shanten Parser allocates a handful of one-million22-element arrays, but it does that within Start()).
So I think that’s all the pre-existing problems,23 which—by way of transition—brings me to the fated statement that roped me into this whole mess:
“I don’t think shanten can be calculated without backtracking.”
Solution
Hey, so, uh, does depth-first search count as backtracking?24
Let’s lay the jargon on the table: The Shanten Parser is a depth-first search through the space of all possible parses of a mahjong hand for the parse or parses with the best shanten. It is written in a recursive fashion, somewhat similar to a computer language parser. However, unlike most parsers25, The Shanten Parser is written using struct-of-arrays style. A parse is a sequence of melds and protomelds that consume various tiles of the hand. The parser uses an early-out to cull search paths that will never surpass the best-seen shanten up to that point. It walks a sorted riichi hand, building up a doubly-linked parse tree as it goes. A successful parse—one that meets or exceeds the best-seen shanten up to that point—is noted by putting a pointer to its tail end into an array of said successful parses. The Shanten Parser is written using struct-of-arrays format and is integrated into the mahjong game as a timesharing coroutine.26 In the rest of this article, we’ll go over how a parse works, the motivation behind some of the decisions made, and some performance numbers.
Before we proceed, I do want to make a note: nothing I say here is meant as a disparagement of the original author of the mahjong game in question, AozoraMahjong, that I’m modifying. Aozora, as a program, is struggling against an adverse programming environment and is a network game forced to work with a uniquely terrible network27 and a programming environment that is actively fighting against it. Aozora is engineered for robustness in the face of adverse network conditions above all else, even performance, when demanded; in an environment where the documentation itself warns against looping over more than 40 or so objects in a frame, Aozora renders out the position of every single object in the game—there’s about 150 or so of them per table—on every table update instead of doing some sort of differential update for fear of desynchronization due to the awful networking; messages have no guarantee of arrival and, if not received, they simply disappear into the void without a trace.28 On top of this, it is working in an environment where the basic data structures used in, to a first approximation, every single C# program are gone. Dictionary? List? Not here. And if you do have the wherewithal to try to build those out of the box of scraps that is U#, remember that you do not have dynamic allocations or user types of any sort.29 On top of this, the personal experience and background I bring to this particular corner of Riichi-Implementing Problems are kind of weird—like, really, who looks at formula like this: 8 - 2*CompletedMeldCount - IncompleteMeldCount - {one or more pairs: 1; no pairs: 0} and goes “What we need is a parse tree!”? That’s probably not a large pool of people. I’d believe you if you told me that’s a pool of one.
So, about that parser decision—that one I have the least to write about because it was a decision made on instinct. I had been working on a little calculator bot30 that built itself a parse tree for stuff like 4+1*(2+3)\^6, so the concept of parsing computer languages was fresh in my mind. As I chewed on the problem of shanten, I noticed I kept phrasing it as “parse shanten”—I was talking about it as if it was a parsing problem. So I decided to treat it as a parsing problem, and that determined the form of the solution I came up with. Aiding in this decision was the need for whatever solution I came up with to be able to handle hands of any size: a mahjong hand can have from 1 to 14 tiles in need of disambiguation for shanten; though a hand usually fluctuates between 13 and 14 tiles as you draw and discard, you can also make fixed melds of tiles by stealing opponents’ discards. This takes tiles out of your hand and forces them to be the meld that you called out when you yoinked that tile; they’re now wholly unambiguous and do not interact with any of the other tile values in your hand for shanten. Something that walked the mahjong hand in some fashion would work just fine, and that’s exactly what a parser does.
Walkthrough of a Parse
So, how do we walk a hand? First, we sort it, primarily by suit (manzu, pinzu, souzu, honors) and secondarily by value (1-9; East, South, West, North, White, Green, Red). The internal representation of the tiles compresses things like suit and value into bitfields in such a way that sorting the tiles as if they were integers naturally performs this two-tiered sorting (this is a native Aozora feature—and Aozora also brought a tile-sorting function with it, which is very handy). This makes searching for things like consecutive tiles and same-faced tiles a matter of looking a tile or two over, not a search through the whole hand (is that the siren song of O(n²) off in the distance? Best not approach…).31 It also ensures that—in the case of nodes that care about whether tiles have consecutive values—we only have to think about consecutivity in one direction (as-implemented, this direction is “ascending”)—that is, if we have ourselves a 3, we only care about 4 and 5, not 2, because any 2 in that suit was stored at a point in memory that we must already have processed to be seeing a 3 (that is, at an earlier point in the array for the hand).
With our hand sorted, we start our walk at the first tile of the hand, index 0. For each of the six possible types of groups that this tile could start—solo, pair, adjacent protorun, split protorun, run, triplet—we first check if there’s material in the hand that could fit the bill: is there another tile with the same value for a pair? If it is not an honor tile32, is there a tile with the same suit and the next number for an adjacent protorun? If the hand does not have the requisite material to form a particular node using the target tile in question as a base, null is returned. If instead the requisite material is present, a node is allocated to store this information as well as some acceleration structures—ok, “some” is a bit of a stretch; a node is mostly acceleration structures by weight. The maintenance and proliferation of these acceleration structures is a good chunk of the code and was the location of many of the bugs; this sort of code is especially vulnerable to typos, due to the kind of thinking required to write it. Acceleration structures are, by definition, redundant data, and the maintenance costs for both the code and the data are good reasons for not including such structures in much code—there is a reason it is exhorted to have only one source of truth for your program. Unfortunately, I could not afford the time cost to not have these structures.
In addition to pointers to including which tiles of the hand this node consumes, as well as the lowest available tile index, which is what we will use if we continue parsing from here (some node types, like split protoruns, may skip adjacent tiles within the sorted hand). If there are not enough tiles in the hand to make the node in question, no allocation is performed and null is returned.33 Having found that the hand does have the requisite tiles to form the group in question (pair, triplet, etc), the node is then run through an early-out function that checks to ensure that parses descending from this node are relevant to calculating shanten, using running counts of what’s present within the parse so far that are members within a node (and include that node itself). If the parse direction is deemed unfruitful, the node is freed and null is returned. If the early-out allows the node through, the node is returned from the parse function for that type of meld and attached to the tree; there’s one slot for each type.
After it has attempted to add all six types of nodes, the parser then checks to see if is over its time budget. If it is (and, as implemented, it always is, as the time budget is set to 0ms), it then skips over recursing into its child nodes to parse what children they may themselves have. Regardless of whether child nodes were further processed, a pass over the children is performed to see if this parse branch has further space to be explored or not—every child must either be null (denoting a branch as impossible or nonviable) or itself be marked as done (which will happen during construction if the node consumes all the remaining tiles in the hand) for the current parse branch headed by this node to be marked done. After that check is performed, the node is marked completed and is returned by-reference. The entry point into the parser always starts at the root node, and when it returns, it returns the address of the root node, which is what is used to check if the whole parse tree is done, using the result of the aforementioned check.
As mentioned, the parser always starts at the root node, even upon resumption. Upon resumption, when it encounters a node marked as completed, it skips over the timeout check and starts recursing into its children. Once it finds a child node that hasn’t yet been completed (that is, a child node that has not yet had its own possible children parsed out of the hand) it starts the parsing process mentioned above, using that child node as the starting point. The timer is not reset, thus including the time needed to find uncompleted nodes in the time budget for that step of the parse. Walking the tree to search for unfinished nodes adds approximately 22% to the total time consumption of a parse 34, but an attempt to make a resumption table to shortcut the walk actually made performance far worse. This could be an area of investigation for future performance improvements, but a more careful design will be needed.
Once the status of a parse branch being done has proliferated back up the tree to the root node—everything beneath it has either reached the end of the hand or had all its child nodes deemed nonviable35 —the parse for that hand is deemed to be done and the results are reported to the player.
The Early-Out
The early-out works as follows: when attempting to add a new node to the parse tree, check to see if this choice of parse direction will send us down a path of no return; a path from where we can never get a better shanten than the best shanten seen so far. This check is performed using a metric called Optimistic Shanten, which looks at the existing parse and the number of remaining tiles and assumes the best case scenario for the remaining tiles. For example, for regular shanten, it assumes all remaining tiles are in three-tile melds and, if there’s two tiles left over after that, it treats them as a pair. For optimistic chiitoi, it adds in the count of how many distinct pairs of tiles are in the hand, unconsumed by the parse (on top of the existing pair count). Optimistic kokushi musou shanten, however, is the same as regular kokushi shanten; they both come from a prepass over the hand.36 As is done with regular shanten, the minimum is taken of these three metrics to get a best-case scenario. If the best-case scenario from continuing down this parse branch is worse than the best shanten yet recorded, then the parser does not follow this parse branch and instead marks it as done.
This works due to an element of shanten’s behavior: when you add a tile, shanten can either decrease by one or experience no change; there is a speed cap, as it were, in regards to shanten getting better as you add more tiles. This maximum speed means that it is possible to irrevocably fall behind; that is, we have consumed so many tiles that don’t improve our shanten that we can’t catch up to the best-seen shanten with the tiles remaining, even if those tiles are as good as they can be. So, if the best parse we could possibly make with what we have in progress is worse than the best full parse for this hand yet, it is because we have a suboptimal parse; therefore, we mark this node as failed and try to continue the parse another way, saving us the time of walking down the rest of the hand. The early-out cuts average time usage by ~53% and worst-case space usage by ~84% in the sample data, which is not bad.
Struct-of-Arrays
This is what required some soul-searching.
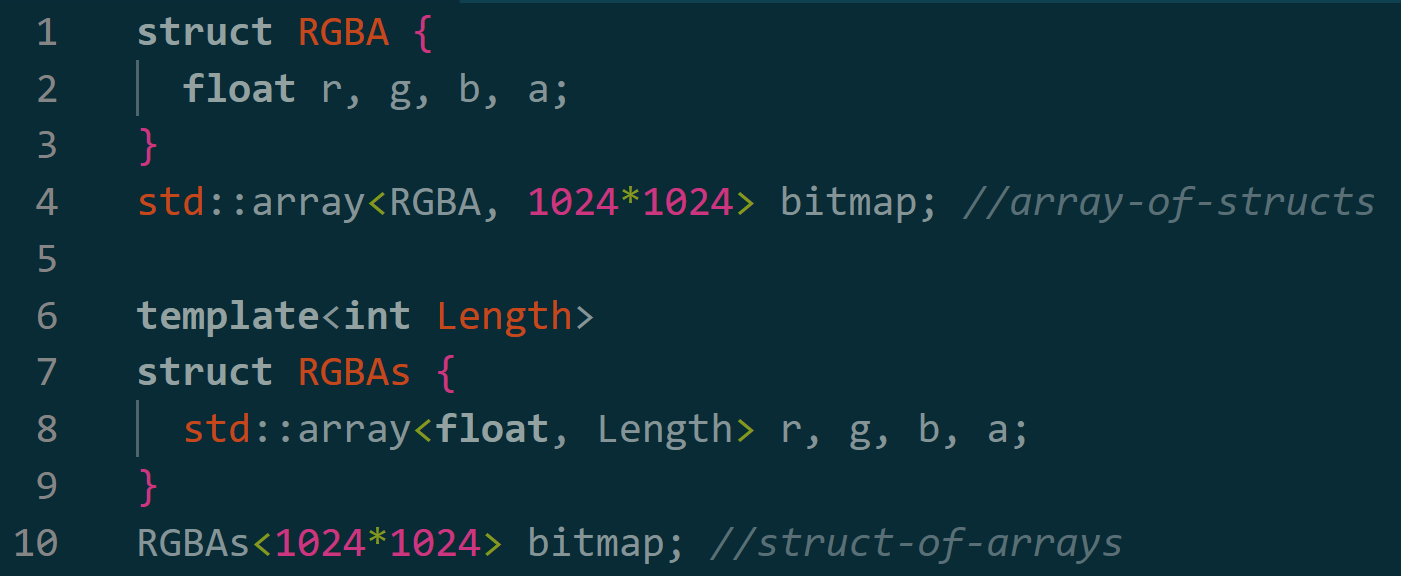
This is the basic idea of struct-of-arrays; take apart a regular class definition and put each member in its own array. This changes the memory layout of the collection—in the above example, instead of [RGBARGBARGBARGBA] it’s [RRRR] [GGGG] [BBBB] [AAAA]. Depending on the access patterns in play—say you wanted to invert the red channel—the latter layout can be friendlier to caching and SIMD operations, CPU- or GPU-side. But I didn’t care about that; I figured that the cache lines and prefetching would just be thrashed by the fact that almost everything in U# gets implemented as a foreign-function call to the .NET runtime37 and then run through a hot mess of checks.
The problem—and the reason I had to dredge around in my soul—is that nothing and no one has support for struct-of-arrays. There are no debug tools for it. There are no library tools for it. The Daily WTF has an entire article against it.38 But I didn’t have types anyway; every tile was an inscrutable, bitpacked integer to the debugger. Debuggers also don’t understand using array indices as pointers. While the logic is the same and the transition is mechanical—obj.member becomes member[obj] and that’s about it outside of changing the member declarations to all be arrays—stuff really starts looking weird. The realization that the transition was merely one of manual text replacement (I am not advanced enough with regex to automate that)—aided by the ability to change all the types of the members first so that I could just follow the red squigglies until I’d fixed them all39—was what tipped the scales for me. I wasn’t going to let Udon beat me. I had a path forward.40
You also don’t have language support when doing struct-of-arrays; you don’t have default initialization, you don’t have nice initializers or support for abbreviated constructor calls, you don’t have any memory management of any sort once you’ve made your arrays. Unless you’re lucky enough to be doing SoA atop autogrowing arrays, you’re also in a rather rarified situation for modern computers with having a limited amount of RAM.41 Those nice squigglies that show up when you forget to initialize something in a constructor? Gone. Default initialization? Gone. All the compiler’s help for managing memory and making sure you’re not forgetting something no longer works. You are on your own when you’re doing struct-of-arrays and you are going to find out why people put the computers on watch for memory-wrangling shenanigans.
But the traditional memory management itself—allocating and freeing—wasn’t actually the hard part; the parser isn’t long-running. It can, in essence, leak memory because it finishes long before it starts pushing at the bounds of the machine abstractions and—importantly—because it restarts cleanly. If I was, in fact, running on a 1980s microprocessor I might actually run into trouble scraping against maximum RAM with imperfect deallocation, but RAM capacity is, thankfully, not something I have to worry about—so long as I make sure to allocate enough of it on boot.42 See, the parser reuses memory from some of the nodes that have been freed during a run—I learned later that what I had come up with was called a “stack allocator”—and reuses the same arrays from run to run.43 What bit me was leaving some fields dirty.44 It actually took a good while into testing for the bite to happen, oddly enough, but that’s why we have computers enforcing memory initialization now.45
To my surprise, when I finally did finished the transformation, struct-of-arrays actually did improve my performance, but this is an algorithm that is very allocation/deallocation heavy that was initially implemented without an object pool, so the transition to a stack allocator being a performance bump is not, in retrospect, that surprising.
Performance
Speaking of performance, let’s break out those numbers! When used, the native C# is running on .NET version 6.0.306 (x64). The U# is running in VRChat—uh, I actually couldn’t find a version number, so I’m reporting this with the Steam Build ID, 10111183; the UdonSharp version within the world project is v0.20.3, and the Unity version46 is 2019.4.31f1. The test machines are as follows:
| Machine Name | CPU Make | CPU Model | CPU Base Clockspeed | CPU Clockspeed During VRChat | RAM Amount | RAM Type | RAM Speed |
|---|---|---|---|---|---|---|---|
| Rehoboam | AMD | 3950X | 3.50GHz | 4.20GHz | 2x8GB | DDR4 DIMM | 4400MHz |
| Red | Intel | i7-6700HQ | 2.60GHz | 3.15GHz | 2x8GB | DDR4 SODIMM | 2133MHz |
| September | Intel | I5-2400S | 2.50GHz | 2.59GHz | 2x2GB | DDR3 SODIMM | 1333MHz |
I did have a machine that was even more potato than an Early-2011 iMac, but VRChat would not run on it.47
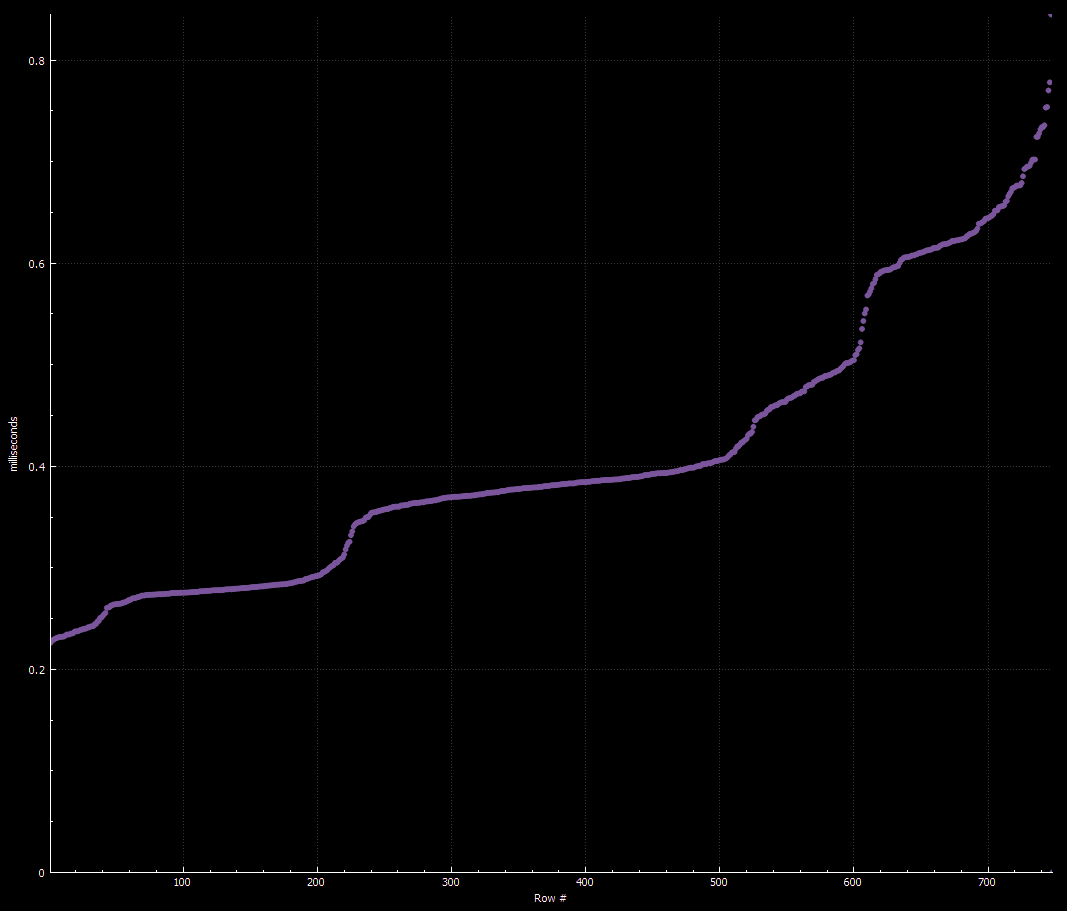
Let’s start with the end result: the amount of frametime each step of the shanten parsing takes out of each frame it’s active. The following chart is from Rehoboam. It shows the amount of CPU frametime devoted to parsing shanten per-frame, sorted from shortest amount of time to longest. In this and the following discussion around numbers and performance, the individual numbers will be color-coded to make clear which machine they came from, using the colors shown in the table above.
Enlarged to show texture
A short test game of riichi mahjong generated 749 parse steps, which used an average of 0.407ms/frame while the parse was ongoing. The worst-case parse time was 0.8448ms, with a runner-up of 0.778ms. So—we did it! We came in under budget!48 At least On My Machine™️. People try to run VRChat on some real potatoes out there, so how does it do on some of the old machines I have lying around?
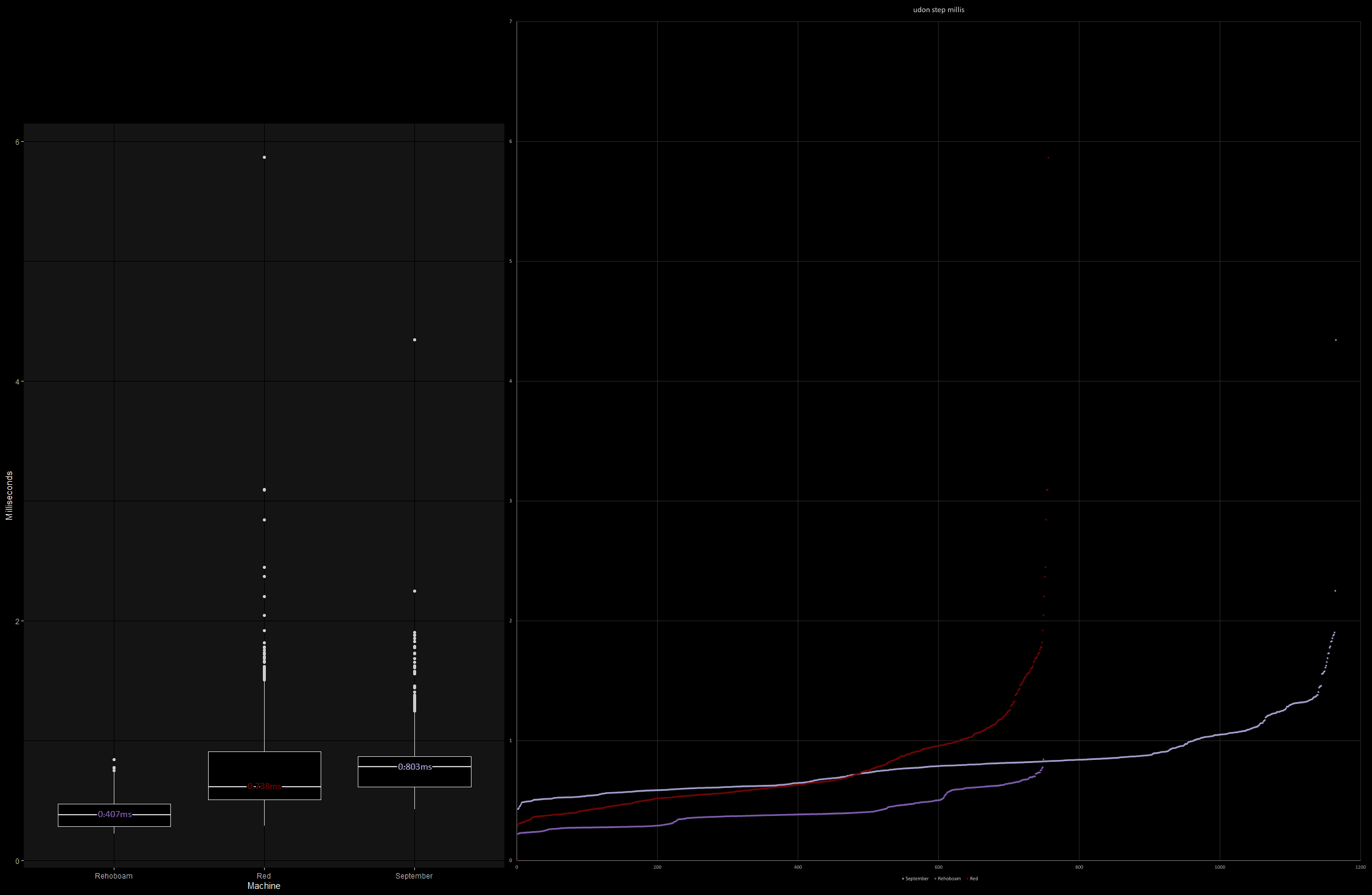
Well, so much for having a nice, clean graph. I wish I knew what was up with those crazy outliers screwing up my axes. Maybe a wretched task switch or something, but that kind of nasty trail-off is exactly what you don’t want in a realtime application, where maximum time guarantees are usually more important than average times. That said, we do have at least three quartiles under budget on all three machines, so that’s something. However, while September is not the kind of machine that’ll serve as a rendering server for an HMD—it was hitting 32fps inside the VRChat world in question while rendering at approximately 800x600—hook an HMD up to that thing to experience falling over instead of VRChat49—The Shanten Parser is a pure CPU workload50, so it’s very possible somebody’s out there with an ancient CPU and a recent-enough GPU to keep SteamVR happy—Red, for instance, doesn’t have that much more CPU grunt than September (they both actually have less CPU than my phone!) but it can certainly run SteamVR and PS2 games like Rez51 in an HMD. These ancient machines are still relevant52. Profiling The Parser over my test data doesn’t turn up any obvious hotspots, but it’s possible my skills at looking are yet unrefined; often, merely observing the correct problem is the whole battle.
While I’m here, I want to also mention how effective the early-out is; it was even more effective than I was expecting when I wrote it.

It has also only gotten more effective over time as I have improved performance outside of resumption; the early-out cuts out late steps, and more steps taken means more expensive resumptions; the average latency goes from 10 to 14 without the early-out, a 40% increase, but the total parse time goes up by 145%—those later resumptions are really beating the crap out of the performance—oh, hello O(n²); every step deeper into the parse is more and more state that must be rebuilt. Nasty stuff, that. Still, thanks to there only being 14 tiles, the badness is at least bounded. Unfortunately, for now, it’s staying there; even though performance improvements—some spurred by this writeup itself—have made reentry a larger and larger portion of the total frametime, it seems that Udon hates my guts.53 First, let’s look at just how big the reentry overhead is:


Did you know that C# natively prints double.PositiveInfinity as ∞? I didn’t!
Reentry, in native C# on Rehoboam, adds an average 38% overhead (24.5μs/hand with no reentry vs 33.8μs/hand with forced reentry) to the total parse time in the current version of The Parser. Ow. This is almost certainly not evenly-distributed; later nodes in a parse have more tree to reenter through, after all, but this suggests that an average of 38% could be shaved off of the frametime used for node parsing. The Udon overhead is not evenly applied to the code; one performance fix improved perf in C# by 28%, but Udon performance by 38%,54 so the improvement to Udon performance is not entirely predictable. Staring at these numbers suggested to me that the average frametime consumption of shanten parsing could be taken down to 0.296ms/frame on Rehoboam, 0.535ms/frame on Red, and 0.583ms/frame on September, if this overhead could be eliminated in its entirety. Better yet, if it was unevenly distributed, it’d help the most on the worst-performing calls into the parser, having an even bigger effect on our worst-performing frametimes. The current version of The Shanten Parser uses depth-first search; by putting nodes that need their children parsed into a queue instead of recursing into them, I could bypass walking the existing parse tree to find what next needs to be done, as, well, there’s a queue! Incidentally, this would transpose The Parser’s search pattern into breadth-first search and finally eliminate the backtracking, so hey.
This development was done on Red, so here’s where the current version of The Parser stands on that machine:

So after implementing the queue and removing another hallmark of the clarion call of O(n²), on Red, I finally got

…um. Oh, wait, it’s only working on single nodes at a time, now, with a 0ms timeout. Let’s take that up just a little bit.

Ok, now we’re cooking! Let’s crank that timeout back down a bit and see how we’re doing.

That’s a 24% speedup or so, compared to current-version with 0ms, and its frametime consumption should be a lot more controllable—check how close the 99th-percentile step time is to its budget. That’s pretty respectable! It’s time to test this in-world and—well, there’s no pretty pictures this time, I think I must have burned the logs.
Back on Rehoboam, I set the timeout to 0.5ms on a guess, and it was reporting that the shanten parsing was consuming >1ms/frame in Udon—which, at that point, had been sitting at a cool average of 0.407ms. And that was only half of it. Check out that 0ms-timeout report again. See that latency, there, of 3066 frames? That was foreshadowing. Even with a timeout of 0.5ms—more frametime than the current version of the parser used on average, a budget which it exceeded, on average, by more than twice what it was set to—The Parser took enormous numbers of frames to actually finish. What once was unnoticeable latency now became a waiting game. Often I’d be in the middle of picking a tile to discard when the shanten parse would actually get around to updating. Sometimes, I’d be sitting there, remoted into a debug session strapped to my head from almost a thousand miles away, waiting for the number to hurry up and update to be sure it was working—and as the results of the shanten parse trigger the riichi button (a crucial gameplay feature), the increased latency actually did force waiting on the parse result when a hand was in tenpai.55
I thought about trying to tweak the timeout, but making the timeout larger would only make per-frame performance even worse when it was already eating up more frametime than the current version. More frametime consumption and more latency was an unfixable combination; the supposed speed-up did not work and made everything worse. So I scrapped it and the logs are probably in the desert somewhere, just slightly to the left of all those E.T. cartridges.
There’s a good chance there’s still room for performance improvements. After all, inspecting my program logic for this writeup, after some time away from it, found performance improvements that I had missed. There might be some easy avenues towards more performance in the future—there’s some bitpacked acceleration structures that might benefit from being unpacked in some fashion, but many of them are bitpacked simply to bypass Udon’s restrictions around allocating arrays; spreading them out requires something they could be spread out into. If and when VRChat transitions to a WASM-based VM for world scripting, I will investigate. Using a queue instead of tree-walking for resumption might be back on the table, but so might any number of other things; there’s many vagaries of C# performance I am currently unfamiliar with—if the manual availability bitmasks are replaced with BitVector32s, how does that affect performance? Given that the algorithm is very allocation-happy in its current formulation, would even an object-pooled version beat out the allocation performance of the existing stack allocator? Would the overhead of simply being an object recognizable to the runtime make my performance worse? I don’t know. That’s kind of the nasty thing about languages like C#; there’s enough machinery added onto the machinery you yourself write that reasoning about behavior, especially performance-related, can require a lot of knowledge of implementation details of a variety of fields, from syntax to garbage collection.
Bugs
There are no known conformance bugs in The Shanten Parser; to my knowledge, it produces the correct result for all possible riichi mahjong hands and, under all possible inputs within the game, it cannot crash. This is at least partially thanks to crashes and incorrect results bringing down the entire mahjong table. In the case of the latter, an incorrect result will generally either softlock the table or turn a normal, desirable game function into a softlock; though the mahjong game is technically still running, it is waiting for some condition to occur that never will, such as selecting which tile to discard to make a 13-tile tenpai hand—when the task is impossible and there is no such tile. Even worse is a crash; although a softlock is resolvable by abandoning the currently-running game and hitting the table’s reset button, a crash kills all Udon execution for that object. If The Parser ever crashes, the table is dead and the whole world instance must be thrown away and a new one made to have a functioning version of that table.
Though it meets the performance target as I defined it, <1ms of CPU frametime on Rehoboam, I’m staring at that resumption overhead and feeling antsy; that overhead probably counts as a performance bug.
This is not how The Parser started out; there were lots and lots of bugs along the way, but most of them were just typos—forgetting to update a variable, using the wrong variable name. One byproduct of struct-of-arrays style was the easy ability to use uninitialized, dirty RAM; a few of the acceleration structures that had existed in the array-of-structs-style prototype used C#’s implicit initialization of ints to 0 and I had forgotten about that when I made my transposition. The AoS→SoA transition, while largely mechanical, does require special care in the constructor for reasons such as these; initialization is something that is very vulnerable to the kind of typos mentioned above—it’s largely rote, but mistakes are disastrous. Bizarrely, it was well into testing before this error was found, so there’s a lesson, I suppose—uninitialized memory will bite you when and where it wants to; temporal proximity between writing and seeing the bug is absolutely not to be relied upon.
Most of the other mistakes laid in integration with Aozora Mahjong. Aozora is state-based rather than event-based; I default to thinking in event-based terms and as a result, the internal logic flow of Aozora ran against my gut instinct for where things should be; I often found myself looking for states that simply were not there. It took three or four tries to actually have an integration that was actually wired up properly; fitting the concept of a hand update to a system without the concept of an event required tracking down all the states that result from an event that could change a hand. A bit of a lesson in how much the internal logic and flow of a thing can differ from how I’d approach constructing one; I haven’t modified much software from others before, not this deeply.
The one real intent error in The Parser itself—as far as conformance issues go—was an edge case in shanten calculation that was mentioned absolutely nowhere among any of the resources I found on the topic; it had to do with chiitoi. Chiitoi is, very specifically, seven distinct pairs. While playing the game, if you draw a new tile such that you now have a hand consisting of four distinct pairs and two triplets, then—despite having six pairs (the last two being two-thirds of the triplets)—you are actually not ready for chiitoi, despite having the otherwise-requisite six pairs in your hand (chiitoi shanten: 6 - 6pairs = 0). This is because there are two tiles that are in your hand right now that cannot be used for chiitoi: the third members of those two triplets you have in your hand. If you were to draw another match for one of those tiles, you would not be in chiitoi, as you have four of the same tile, two of the same pair—which makes for six distinct pairs and not the seven you actually need. It took me quite a bit of staring at the hands that caused the softlocks to finally understand what was going on. This spawned a prepass that counts up how many times trios appear within the hand, specifically to catch that scenario and set chiitoi shanten back to 1.
Takeaways
You will see advice against writing stuff in struct-of-arrays format, and it’s a decent general rule; the tooling just is not there to make it work cleanly; debuggers and visualizers have no idea what you’re doing, and you kinda can’t tell them, either. The foundations of this algorithm were sketched out in array-of-structs format to begin with. If I didn’t have a foundation—built with proper tooling—to make that mechanical transition to SoA from, The Parser would have assuredly taken much longer, and perhaps not come to fruition at all. If you find yourself backed into a corner and SoA is your only way out, maybe sketch out your program in AoS form first, and then go in and make that conversion after you’ve gotten it working and debugged. Honestly, much of the code looks so bizarre that, had I not written it, I’d probably reject it on sight if somebody offered it to me. SoA is incredibly useful for certain niches beyond working in bad programming environments—if you’re often iterating over just one member of the object, having them all in one array is better for cache performance and vectorization, and sometimes necessary for things like uploading to a GPU—so it’s a shame there isn’t better support for it; a collection class would be a good first step, but it probably requires some metaprogramming to make work and/or compiler support.
That said, without struct-of-arrays, this parser could not have been built in Udon, which would have been a shame; it’s a genuinely massive improvement over the prior state of the table. The Shanten Parser means people wanting to play riichi mahjong in VRChat no longer have to brace themselves when they hear the chime informing them that it is their turn. By and large, they can just sit there and play the game with their friends and not have to worry about the performance characteristics of the mahjong table or anything else under the hood. People often give advice that is good in general without that caveat;
When you’re operating in strange programming environments, performance characteristics can be absolutely wild; I had no reason to expect using a queue to resume parsing nodes would be anywhere near as awful for Udon performance as it turned out to be.
Other people’s code—especially the inner guts of it—can be really, really different than how you would natively model the problem at hand, and it’s easy to go on a wild goose chase trying to track down an implementation of a thought that they didn’t have and didn’t need. Perhaps this is obvious to people who are used to such things, but I am not (yet).
Having a huge test suite to throw The Parser against was a lifesaver; bugfixes and regression checks are as easy as hitting F5. That said, the awfulness of U# development means that most development is actually done in separate files in this native-C# test environ, then manually copied into the U# code. Manual copying is tedious and error prone, try to make your workflow not rely on it, if at all possible.
Unity, as an engine, does not play nice with Git.
Sometimes, when you’re backed into a corner, you just gotta throw weird solutions at a problem. Sometimes you can unweird them later, sometimes not. Good luck, and may your problems not be cursed.
-
There is also a four-tile meld that you can make by separating the full quartet of same-faced tiles from the rest of your hand; for most purposes, however, it counts the same as a triplet. ↩
-
Technically, you can discard the winning tile, usually to try and get a better win, but it’s a very risky play for a number of reasons and usually not worth it. Riichi is full of these “You can do this unusual thing, it’s only usually a bad idea.” caveats; they’re just kind of everywhere in this game. ↩
-
There’s a really nasty edgecase here that I ran into firsthand. It’s in the bugs section. ↩
-
Now I’m thinking about the possibility of modeling riichi hands in some sort of space that uses shanten as a distance metric and now I have to get out of here before I get nerd-sniped. ↩
-
For shanten is distance to tenpai, after all. ↩
-
It has to do with theory-of-mind; theory of mind is necessary to have a proper conversation, and it seems that the maximum number of minds a human can reason about is five; themself, the three other people in a conversation, and what they think everybody else thinks they’re thinking. ↩
-
feat. endless falling and no ground ↩
-
Where these parses differ in practice is which tiles could improve the hand, and here ambiguity is actually your friend; the more ways to parse a hand, the more ways you have to progress it, increasing how many individual tiles could improve your situation and, thus, your odds of drawing one. ↩
-
There is a fourth suit, honors (abbreviated
z), but they’re difficult to work with—only making pairs and triplets and rendering you ineligible for some common win conditions—rendering them often not worth it, so not having any in your hand is pretty common. ↩ -
A quirk of this parser is that, as solo tiles do not decrease shanten but instead negatively impact the ability of the rest of the hand to decrease it, the parser will—depending on hand structure—sometimes produce parses that don’t use the entire hand. These parses still have accurate shanten. The parser did, in fact, produce a handful of parses that did not consume every tile in this hand—leaving out, say, that 7s at the end when it was a solo tile—but I have filtered them out here for clarity. Exactly why the parser stops parsing in these situations will be explained later. ↩
-
This hints at a general behavior within riichi: hands with bad shanten usually have many routes to becoming better—with all those ways to parse a hand, there’s probably a few that will improve if you accept the tile you just drew and pitch something else. Thus, hands with poor shanten will often improve relatively quickly; poor shanten within your hand isn’t necessarily a game-killer, at least at the beginning of the round. ↩
-
Also you’re wondering if your lips might be turning cherry red the entire time. ↩
-
Actually, what’s thicker than molasses? Pitch? Yeah, pitch. ↩
-
Cars are probably the most-common instance of this property, or at least the one you and I have most recently interacted with in some fashion. Next up is probably industrial process-monitoring software, the kind that shuts down the centrifuges if they’re doing something wacky. ↩
-
yay! ↩
-
If you’ve never experienced this, by the way, it’s surreal; if it’s prolonged, the world itself suddenly drags along with you, instead of being in a fixed place while you move within it, like a world should. This is such a jarring experience that software responsible for feeding frames to HMDs will actually make up whole new frames if the application doesn’t give it a new frame in time for the next display cycle. Oculus’s middleware has a couple of variants of this feature, called “Spacewarp” and “Asynchronous Spacewarp”; other middleware may call it something different. This process is not free of artifacts and only has information pertaining to the difference in head position between the last frame and this one; actions taken within the program (like moving your arm around within the world) will not have their effects shown until the next frame rendered by the application itself makes its way to the user’s eyeballs. So, although spacewarp ameliorates minor performance hiccups, the motion depicted in the resulting video is less smooth than desired, as a frame depicting in-application motion or action has been delayed or has disappeared entirely. In addition, spacewarp and friends typically only work for so many frames after the last-rendered frame, whereupon the video will either freeze on the last frame delivered, or the software will give up and start displaying a different environment for the user, rendered by an application that can be trusted to keep up with the user’s head motion (eg: SteamVR default world, which will show up after ten consecutive missed frames). ↩
-
I haven’t seen any headsets out there with variable refresh rate, but it seems like a pretty obvious feature to me. I wonder what’s holding it back… Maybe it doesn’t work as well when strapped to a face? If you know, please write in! ↩
-
owie ↩
-
Source: Personal conversation with SO, 2022-Oct. ↩
-
I think the readability of the code is ok for what it is, but what it is makes it, among other things, more difficult than usual to debug. ↩
-
2²⁰ ↩
-
Well, that affect this parser, anyway. ↩
-
I hope? ↩
-
The parses can be used for other riichi-related things, such as finding which tiles would bring the hand closer to completion, but this functionality is currently unused. It is occasionally helpful for debugging, however. ↩
-
Udon networking is a level of atrocious that makes me astonished anything at all works atop it. ↩
-
I am unaware of anything standing between Unity and a reliable network connection; the C# used by Unity for running CPU code is perfectly capable of opening up TCP connections. Even though TCP—which does ensure message delivery—is unpopular in realtime settings due to having the potential for drastic latency spikes,57 these spikes in latency are not large enough to interfere with things like turn-based games. I am unaware of why Udon does not offer the ability to open a reliable TCP connection between players to transmit data in applications that care more about getting the data transferred than worst-case latency. ↩
-
Compounding the lack of objects for memory and code organization, U# also doesn’t allow partial classes, denying you even that amount of code organization. The .cs file that implements the mahjong game itself is long enough to make my VSCode installation stall so frequently while editing the file that it is unusable, and VS2022 takes several seconds just to update syntax squigglies. ↩
-
It was originally envisioned as a dice-rolling bot but the calculator feature became the bulk of the code—and most of what I use it for. ↩
-
Alas, while writing this writeup, I found a place where I had succumbed to O(n²) and was looping through the hand on every node construction58. After fixing it, the average performance increased by 22% for a full parse in C# and 39% per parse step in U#.59 ↩
-
Although, for logistical reasons, the honor tiles do have numbers associated with their faces and a defined sorting—an East tile is notated as a 1z—this is purely a notational and sorting aid. By the game rules, the individual honors values are unordered with respect to each other, so there cannot be a run of honors tiles, as there is no order to have three of them in to begin with. ↩
-
Allocating a node is performed using a stack allocator which simply increments up for every allocation and decrements by one if the freed node is at the top of the stack, counting off the available indices for the struct of arrays.60 ↩
-
Unless something wacky is going on, I believe the overhead is concentrated towards later parse steps, as those have more tree to walk through, but the exact curve is unknown to me, so I have listed here the number I do have, which is for the overall parse. ↩
-
The existence of a node that just takes one, single tile means that there will always be a way to progress forward in a hand, unless the early-out burns down that path. This is why parses aren’t guaranteed to use all the tiles of a hand—these parses are still correct, however. ↩
-
Kokushi shanten is, blessedly, not ambiguous; “how many different kinds of nonsimple tiles are in this hand” is relatively easy to answer for a computer, and adding in a check for a pair is pretty simple as well. ↩
-
From within a VM running on top of the .NET runtime! ↩
-
After reading the comments, it turns out that “parallel arrays” is another name for SoA, and that I am not the first to use it to get around a lack of custom object types; I didn’t think I was, not by a long shot, but I find it interesting that this is also considered an old technique for working around language limitations regarding memory organization—I turned the Wheel of Samsara on purpose and, when I wasn’t looking, it turned on me. ↩
-
This is really useful, honestly. In general, I try to engineer my changes like this to make the compiler do as much work for me as I can. ↩
-
Seriously, though, Udon probably counts as a crime against nature.61 ↩
-
Modern machines do their absolute damnedest to pretend to have unlimited RAM. This is actually the fundamental premise of garbage-collected languages. Non-garbage-collected OSes62 will do things like slap RAM contents onto disk and kill random processes(!) to maintain the illusion of an infinite pool of RAM. Windows, for example, will actually let you allocate arbitrarily large amounts of RAM, boil-the-oceans amounts of RAM—and only start doing things to your computer if you ever try to actually touch any of it.63 64 ↩
-
Because any single error brings down the whole table until a whole new instance of the world is made, RAM for the parser is actually wildly overprovisioned. With freeing turned on, the maximum number of nodes used at one time in any parse in my test dataset is 3,067, but the parser allocates space for 2²⁰ nodes instead (1,024*1,024, ~a million). This number was picked to be absolutely sure that no hand in the wide, wide world of mahjong could run the parser out of RAM—and because I didn’t have the instrumentation over my test dataset then that I do now. Anyway—in native code at least, but my understanding of U# and .NET suggests this should be the same in Udon—this is 94MB/mahjong table for the nodes themselves, with another couple MB for per-parse information. What might change this number is a CPU architecture change, but I don’t have a ready .NET ARM environment handy and there is no Quest version65 of this world anyway66 ↩
-
You probably know where this is going. ↩
-
C# outright refuses to compile a program if you try to read from a variable it can’t prove has been initialized yet. Unfortunately for the parser, methods like struct-of-arrays mean that the variables that C# can see have been initialized—that’s the on-boot memory allocation—and there’s ones it can’t see that can become dirty, uninitialized memory. This is a hazard of writing things in array-of-structs style first; the automatic memory-initting done by the language itself means that there’s no explicit memory-initting code for you to transform. Ow. ↩
-
At the time of this writing, the Unity version is the same for all updated VRChat Worlds ↩
-
EAC ↩
-
…After I fixed an instance of O(n²) while writing this thing, anyway. ↩
-
Poor thing’s running a laptop GPU from 2010, give it a break.68 ↩
-
My benchmark for it actually does peg a core to 100% for its duration, so it’s at least using the CPU, although perhaps it could use it better. ↩
-
I think it’s interesting that the HMD port of Rez is the best version of the game, as it has the best cursor control of any version—you paint targets by just pointing your controller at them. It feels direct. Prior releases are stuck with a thumbstick as an input mechanism for a 2D cursor,69 and the flatscreen version of Rez maps the ingame cursor to the movement of the mouse in a rather bizarre way70 (there’s also significant latency between mouse movement and it being reflected in cursor movement). Given the high price of an HMD, it’s rather a shame that Rez Infinite’s mousefeel is so poor, as the game otherwise runs well on what is now rather low-cost hardware. ↩
-
Often, enforced by wallet. ↩
-
This technology is slandering the soup. ↩
-
weird coincidence ↩
-
TCP does ensure that messages arrive at their destination, but it also has the sometimes-desirable property of always ensuring they arrive in order. This may not be desirable in certain circumstances where low latency is king, as if messages arrive out of order (whether due to retransmission or other network shenanigans) TCP will hold later messages in queue while it waits for the earlier one to arrive. This potential for unpredictable, possibly drastic latency spikes makes TCP unpopular for applications where latency is the enemy and later packets correct or override the missing data. ↩
-
ffs ↩
-
!! ↩
-
As basic as this is, even this simple sometimes-freeing cuts peak node consumption roughly in half. ↩
-
This is not an appeal to some imagined natural order, but an appeal to not causing CPUs to consume 1000x as much energy as they should to do any scripting at all in VRChat. ↩
-
Everything but Midori and anything that ran on the i43273? ↩
-
The relevant Win32 call here is VirtualAlloc, which reserves some virtual addresses for you in your process’s virtual memory map which will then soft page fault if touched, trapping into the OS to actually grab you a piece of silicon to store your data in (and, if needed, kick some other process’s memory out onto, uh, the slower silicon74). ↩
-
Also the referenced zfs ‘article’ is here and the ocean-boiling quote is at the bottom; it’s the only slice of humanity in what is otherwise a simpering, fellatious ad. ↩
-
VRChat has a severely downgraded and crippled75 version of its client that runs natively on the Quest 2, an HMD that is, essentially, an Android tablet attached to a headband—just like every other standalone HMD. The Qualcomm XR2 SoC76 is ARM-powered. ↩
-
We tried making one and even before trying to turn a table on, with none of the expensive effects turned on and my clock77 turned into an error shader showcase, performance was so dreadful—and the world looked so genuinely terrible, especially with its textures so horrifically crunched—that we decided our attention was best placed elsewhere for the time being. ↩
-
If you didn’t call it, totally pretend you did. ↩
-
Though physically a 2D input mechanism, thumbsticks work most comfortably when parsed as 1D input devices into either a toroidal79 or—less comfortably—Cartesian space.80 Their small size makes input imprecise—mapping small amounts of 3D space to large amounts of 2D space—forcing, in the case of both cursors angular81 and rectangular82, low maximum speeds to produce an output space matching the small size of the physical input space. These speed caps leave the user staring at the cursor, waiting for it to align with the thing they want to point at83; compare this to a SHMUP, where one of the main objectives is to move a cursor to avoid targets; in that scenario, the game is actively making you plot out a path for your cursor with the limitations of its speed in mind—on top of the task of keeping as much of the path of the cursor within a particular subset of the total space as possible (so your own shots can hit stuff). In a thumbstick FPS, you plot a straight line to where you think your target is going to go and then you wait for the cursor to get over there. It’s not an interesting waste of time. ↩
-
The game is functionally played in projectionspace, so you should be able to just use the regular OS cursor’s position instead of transforming it; I’m at a loss to explain this from the outside. ↩
-
The removed features of the Quest port severely hamper the self-expression half of VRChat. For some, the self-expression is the whole point. ↩
-
Also omnipresent. ↩
-
It’s an analog clock with an emissive shader and the reason bloom is enabled in that world. It’s also implemented as a day-long euler animation because I thought that was funny (and also because it eschews as much Udon as possible—it resyncs itself once a minute though because I have no idea what amount of accumulated error to expect). ↩
-
gateriding ↩
-
steering in a racing game ↩
-
first- and third-person shooters ↩
-
mouse cursor ↩
-
Remember that the i432 started development in 1975. In 1975 the user-based security model of computers was already known to be fundamentally broken and unusable and fifty years later every single computer is worse off for it, from the excuses it provides for destroying human agency to the horrifying performance of security solutions that actually work (Udon). ↩
-
please don’t boot off HDDs any more I’m begging you ↩
-
リーチ! ↩

